一. 百度site结果
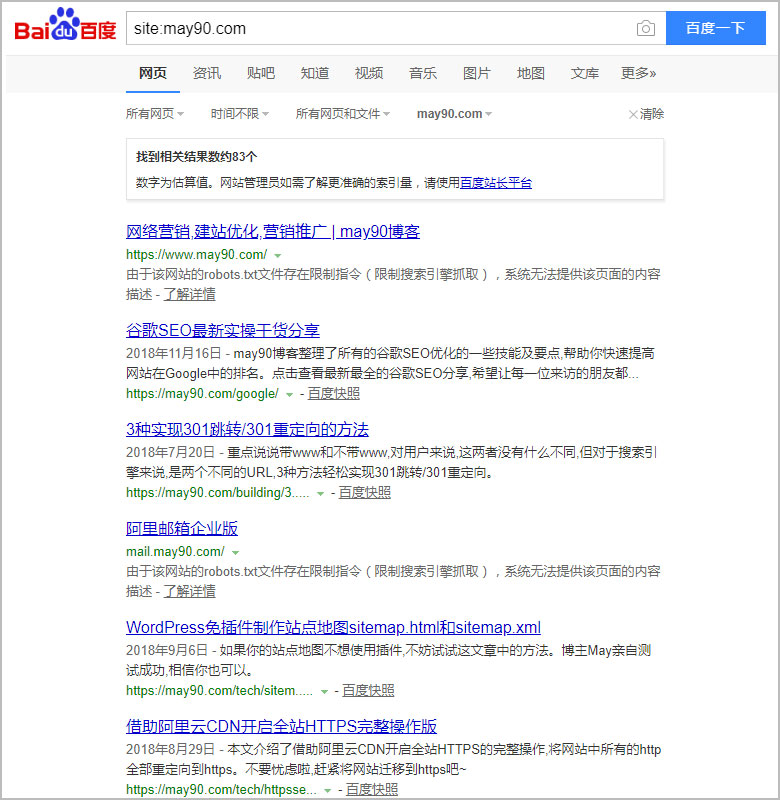
May使用site指令在百度上粗略查询网站收录量时,发现一个问题,site:may90.com,发现搜索结果中竟然含有带www的may90.com。
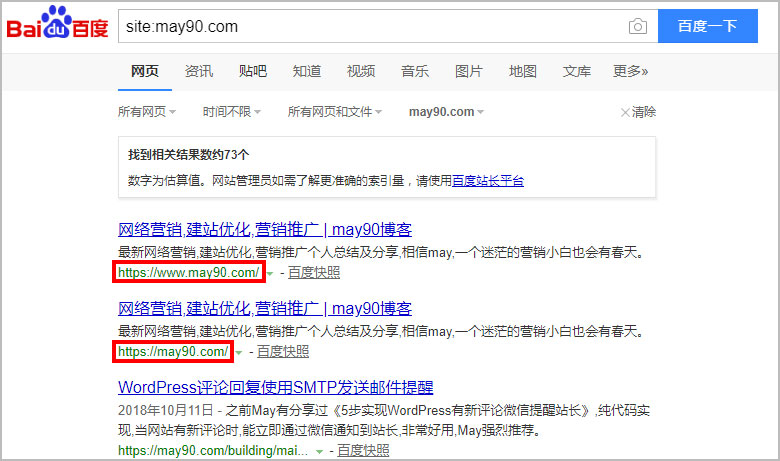
带www的may90.com竟然排在第一位;may90.com排在第二位。于是又在百度上搜索了一下,结果如下:
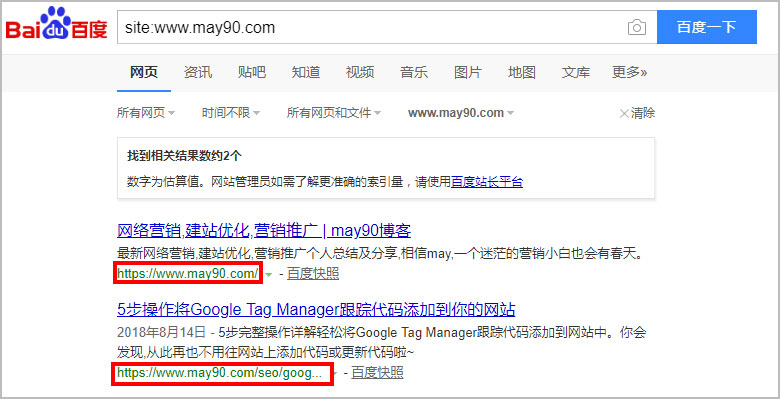
这个结果让May特别地意外。May在建站初期就确定了网站的首选域,将may90.com作为首选域。
二. 站长工具检查首选域
在站长工具中也能查询到将带www的域名跳转到不带www。
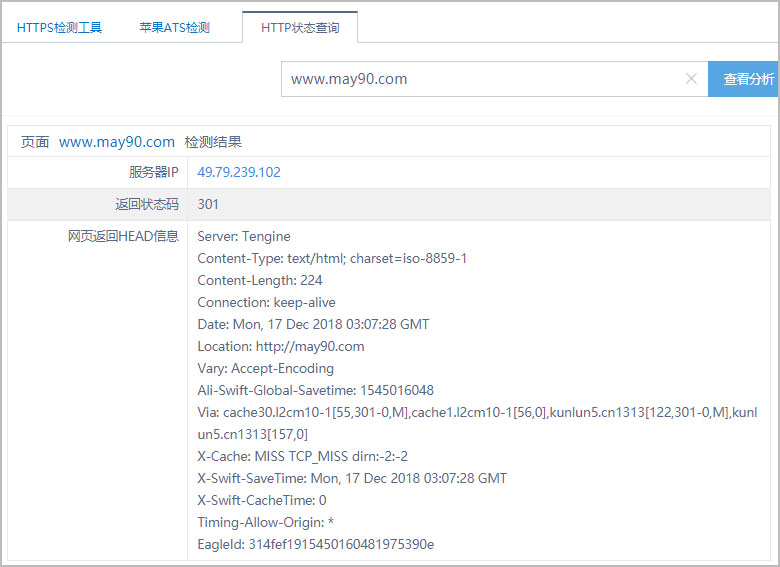
三. 谷歌site结果
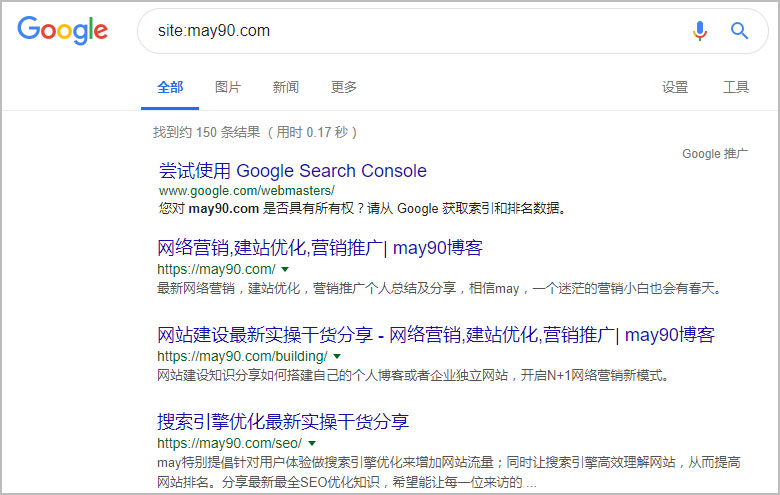
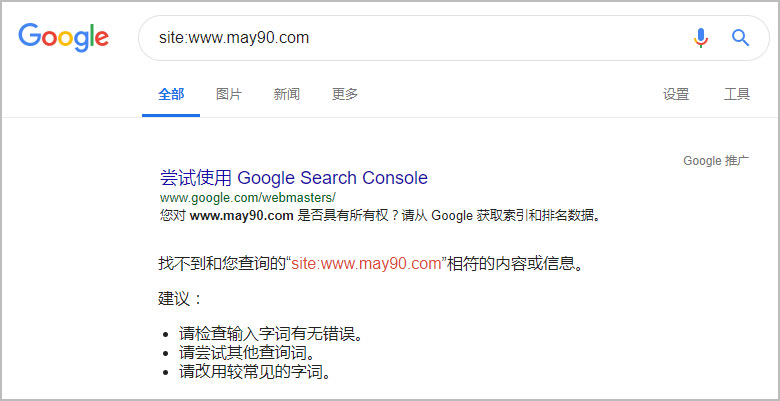
Perfect~谷歌的这个结果让我特别满意,Google完全认可首选域的设置。难道百度不认可301跳转?对于百度,我也只能呵呵了。百度同时收录了带www的may90.com和may90.com这样极易造成大量重复页面的产生。
四. 解决方法
1.在WordPress主题根目录新建wrobots.txt,代码如下:
User-Agent: * Disallow: /
告诉搜索引擎禁止收录任何内容。
2.May使用的是虚拟主机
RewriteEngine on
RewriteCond %{HTTP_HOST} ^www.may90.com [NC]
RewriteRule ^robots.txt wrobots.txt [L]
告诉搜索引擎带www的may90.com收录请参考wrobots.txt,禁止收录带www的may90.com的所有内容。
3.百度投诉快照
将带有www的链接到百度投诉平台进行投诉。
五.检查
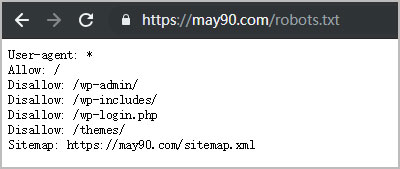
1. 在浏览器地址栏输入:may90.com/robots.txt
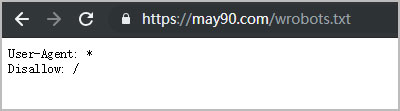
2. 在浏览器地址栏输入如下,会直接跳转到may90.com/wrobots.txt
上述写于2018年12月17日。
2018年12月20日,再去查看带www的may90.com的收录情况,只剩下1条记录了,且提示:
由于该网站的robots.txt文件存在限制指令(限制搜索引擎抓取),系统无法提供该页面的内容描述。
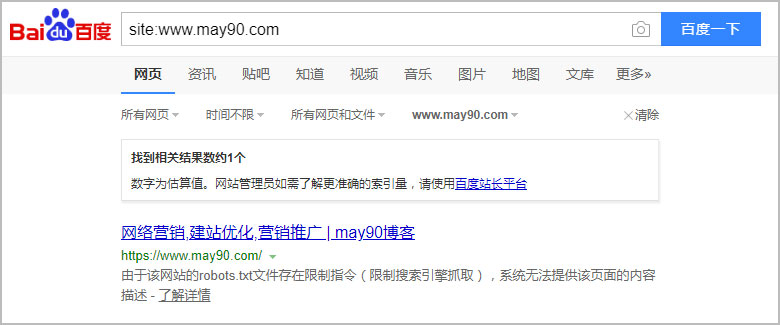
说明带www的may90.com的robots.txt已经开始生效了。但是百度依然还会索引这个非首选域名。愤怒~
2018年12月21日,再次查看site:may90.com的结果,竟然找不到may90.com,百度是不是抽风了?
所以这种方法只适合新站点的设置,对于老站点还是无法屏蔽非首选域。